|
AI Engine Intrinsics User Guide
(AIE) r2p23
|
|
AI Engine Intrinsics User Guide
(AIE) r2p23
|
The basic functionality of these intrinsics performs vector multiply and accumulate operations between data from two buffers, the X and Z buffers, with the other parameters and options allowing flexibility (data selection within the vectors, number of output lanes) and optional features (different input data sizes, pre-adding, etc). There is an additional input buffer, the Y buffer, whose values can be pre-added with those from the X buffer before the multiplication occurs. The result from the intrinsic is added to an accumulator.
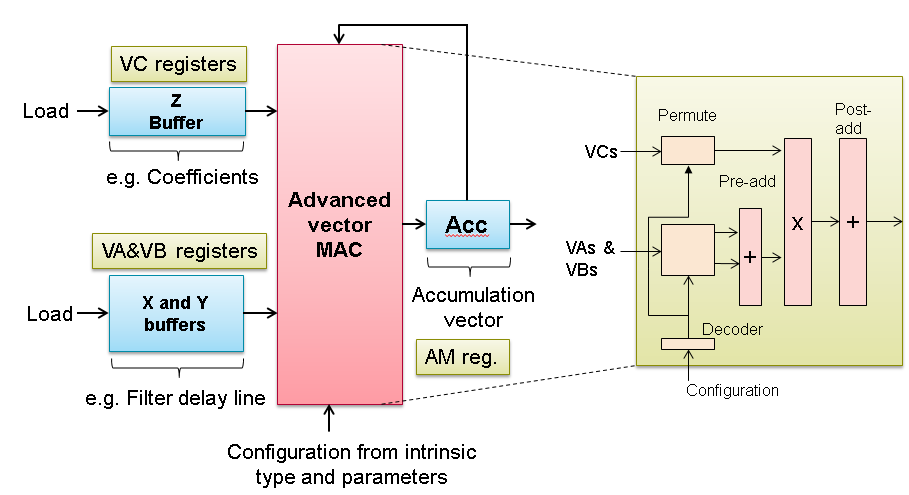
This diagram gives a functional overview of how these intrinsics work. For users who are familiar with FIR filters, in this scheme X and Y can be used for data and symmetric data respectively and Z for the coefficients when implementing a symmetric FIR filter for example.
The operation can be described using "lanes" and "columns". The number of lanes corresponds to the number of output values that will be generated from the intrinsic call. The number of columns is the number of multiplications that will be done per output lane, with each of the multiplication results being added together.
Example :
acc0 += z00*(x00 + y00) + z01*(x01 + y01) + z02*(x02 + y02) + z03*(x03 + y03) acc1 += z10*(x10 + y10) + z11*(x11 + y11) + z12*(x12 + y12) + z13*(x13 + y13) acc2 += z20*(x20 + y20) + z21*(x21 + y21) + z22*(x22 + y22) + z23*(x23 + y23) acc3 += z30*(x30 + y30) + z31*(x31 + y31) + z32*(x32 + y32) + z33*(x33 + y33)
In this case, we are generating 4 outputs, so 4 lanes, and 4 columns for each with pre-adding from the X and Y buffers.
The general naming convention for the vector MAC intrinsics is shown below. Optional caracteristics are shown with [] and mandatory ones with {} :
[l]{mac|msc|mul|negmul}{2|4|8|16}[_abs|_max|_min|_maxdiff][_conj][{_sym|_antisym}[_ct|_uct]][_c|_cc|_cn|_nc]
Every operation will either be a multiplication, intitializing an accumulator, or a mac operation which accumulates to a running accumulator, of 2/4/8/16 lanes.
Optional specifications :
The parameters of the intrinsics allow for flexible data selection from the different input buffers for each lane and column, all following the same pattern of parameters. A starting point in the buffer is given by the (x/y/z)start parameter which selects the first element for the first row and first column. To allow flexibility for each lane, (x/y/z)offsets provides an offset value for each lane that will be added to the starting point. Finally, the (x/y/z)step parameter defines the step in data selection between each column based on the previous position. It is worth noticing that when the ystep is not specified in the intrinsic it will be the symmetric of the xstep.
If pre-adding or pre-subtraction is used (including with conjugation/upshifting or partial), the Y buffer is used for the needed input data. In this case, the selection is done in the same way except it is minus the step. This also applies to when Vector MAC operations are combined with comparisons. In the case of partial pre-adding or pre-subtraction, the final column is without pre-adding and data is selected from the X buffer with the ctap parameter.
When the output has more than 8 lanes (e.g. 16) there are extra offset parameters. Apart from the usual 'offsets' parameter there is an additional 'offsets_hi' parameter for the extra lanes. This extra parameter allows selecting the data that will be placed into the upper input lanes (8-16) of the multiplier.
Permute granularity for x/y and z buffers is 32b and 16b, respectively. The start and step values which are in sample granularity have to conform to the permute granularity (e.g., xstart for int16 data samples cannot take odd values and int8 data samples need to be multiple of 4). The lower level selection of the data samples are carried out of by the mini permute which is controlled by the square parameter.
When both input buffers are 16bit real buffers, or less there are extra selection parameters. Apart from the usual offsets parameters there is an additional 'square' parameter to select between elements of the input buffer. Additionally if the coefficient buffer (usually called zbuff) is a 8bit real buffer it too will possess a square parameter.
| Data | Coefficient | Complex Data | Complex Coefficient | has xysquare | has zsquare | xstart restrictions | xstep restrictions | zstart restrictions | zstep restrictions | Data scheme | Coefficient scheme |
|---|---|---|---|---|---|---|---|---|---|---|---|
| all others | all others | any | any | no | no | signed 32b | signed 6b | 4b | signed 6b | General | General |
| 16-bit | 16-bit | no | no | yes | no | multiple of 2 / signed 32b | multiple of 2 / signed 6b | 4b | signed 6b | 16b x 16b data | General |
| 16-bit | 8-bit | no | no | yes | yes | multiple of 2 / signed 32b | multiple of 2 / signed 6b | multiple of 2 / 4b | multiple of 2 / signed 6b | 16b x 16b data | 16b x8b coefficient |
| 8-bit | 8-bit | no | no | yes | yes | multiple of 4 / signed 32b | multiple of 4 / signed 6b | multiple of 2 / 4b | multiple of 2 / signed 6b | 8b x 8b data | 8b x 8b coefficient |
Converting from an index to a row and column pair
For any given pair of c (column) and r (row) where c can go from 0 to cols and r can go from 0 to rows(number of lanes) in the output vector:
for i = 0 ; i < rows * cols ; i++
c = i % cols
r = i / colsr and c can be used to compute the offset for the corresponding index i
//lanes
lanes = (number of elements in output vector)
//multiplications
int m=1;
if (data_size == 32) m*=2;
if (coeff_size == 32) m*=2;
if (data_complex) m*=2;
if (coeff_complex) m*=2;
//rows and cols
rows = lanes
cols = 32/(m*lanes)
for i = 0 ; i < rows * cols ; i++
c = i % cols
r = i / cols
idx[i] = ( start + offs[r] + step*c ) % (#samples in buffer) for i = 0 ; i < rows * cols ; i++
c = i % cols
r = i / cols
if (r % 2 == 0):
offset = offs[r]*2
else:
offset = offs[r]*2 + (offs[r-1] + 1)*2
xstep = c/2*xstep + c%2
ystep = -(c/2*xstep - c%2)
idx[i] = ( xstart + offset + xstep ) % (#samples in buffer)Once all indexes have been computed the square parameter is applied to each 2x2 matrix where the square parameter chooses the index from 0 to 3 - read as 4b parameters - ( increasing left to right, top to bottom ):
idx[x ][y] idx[x ][y+1] < = > 0 1
idx[x+1][y] idx[x+1][y+1] < = > 2 3The 4 LSB for the square parameter corresponds to the first lane. The above would be represented by 0x3210. Any combination is allowed. For instance, square = 0x2130 would result in:
idx[x ][y] idx[x+1][y+1] < = > 0 3
idx[x ][y+1] idx[x+1][y ] < = > 1 2
cols = 64/(m*lanes)
for i = 0 ; i < rows * cols ; i++
c = i % cols
r = i / cols
offset = offs[r]*2
step = c/2*zstep + c%2
idx[i] = ( xstart + offset + step ) % (#samples in buffer)Once all indexes have been computed the square parameter is applied to each 2x2 matrix where the square parameter chooses the index from 0 to 3 - read as 4b parameters - ( increasing left to right, top to bottom ):
idx[x ][y] idx[x ][y+1] < = > 0 1
idx[x+1][y] idx[x+1][y+1] < = > 2 3The 4 LSB for the square parameter corresponds to the first lane. The above would be represented by 0x3210. Any combination is allowed. For instance, square = 0x2130 would result in:
idx[x ][y] idx[x+1][y+1] < = > 0 3
idx[x ][y+1] idx[x+1][y ] < = > 1 2
cols = 128/(m*lanes)
for i = 0 ; i < rows * cols ; i++
c = i % cols
r = i / cols
rx = r / 2
rr = r % 4
if rr == 0:
offset = offs[rx]*4
else if rr == 1:
offset = offs[rx]*4 + 1
else if rr == 2:
offset = offs[rx]*4 + ( offs[rx-1] + 1 ) * 4
else if rr == 3:
offset = offs[rx]*4 + ( offs[rx-1] + 1 ) * 4 + 1
xstep = c/2*xstep + (c%2)*2
ystep = - ( c/2*xstep - (c%2)*2 )
idx[i] = ( xstart + offset + xstep ) % (#samples in buffer)Once all indexes have been computed the square parameter is applied to each 4x2 matrix where the square parameter chooses the index from 0 to 3 - read as 4b parameters - ( increasing left to right, top to bottom ). In this case, because the matrix is 4x2 and only 4 indexes exist, the indexes from the even rows are duplicated for each odd row:
idx[x ][y] idx[x ][y+1] < = > 0 1
idx[x+1][y] idx[x+1][y+1] < = > 0 1
idx[x+2][y] idx[x+2][y+1] < = > 2 3
idx[x+3][y] idx[x+3][y+1] < = > 2 3The 4 LSB for the square parameter corresponds to the first lane, first column and second lane, first column. The above would be represented by 0x3210. Any combination is allowed. For instance, square = 0x2130 would result in:
idx[x ][y] idx[x+2][y+1] < = > 0 3
idx[x+1][y] idx[x+3][y+1] < = > 0 3
idx[x ][y+1] idx[x+2][y ] < = > 1 2
idx[x+1][y+1] idx[x+3][y ] < = > 1 2
for i = 0 ; i < rows * cols ; i++
c = i % cols
r = i / cols
rz = ( row / 4 ) * 2 + ( row % 2 )
offset = offs[rz]*2
step = c/2*zstep + (c%2)
idx[i] = ( xstart + offset + step ) % (#samples in buffer)Once all indexes have been computed the square parameter is applied to each 4x2 matrix where the square parameter chooses the index from 0 to 3 - read as 4b parameters - ( increasing left to right, top to bottom ). In this case, because the matrix is 4x2 and only 4 indexes exist, the 2x2 indexes simply replicated twice.
idx[x ][y] idx[x ][y+1] < = > 0 1
idx[x+1][y] idx[x+1][y+1] < = > 2 3
idx[x+2][y] idx[x+2][y+1] < = > 0 1
idx[x+3][y] idx[x+3][y+1] < = > 2 3The 4 LSB for the square parameter corresponds to the first lane, first column and second lane, first column. The above would be represented by 0x3210. Any combination is allowed. For instance, square = 0x2130 would result in:
idx[x ][y] idx[x+2][y+1] < = > 0 3
idx[x+1][y] idx[x+3][y+1] < = > 1 2
idx[x ][y+1] idx[x+2][y ] < = > 0 3
idx[x+1][y+1] idx[x+3][y ] < = > 1 2An example on the use of the 'square' parameter can be the broadcasting of data to multiple multiplier input lanes. One such practical case would be 16bit real x real FIR application where we would require the following pattern:
acc[0] = xbuff[0]*coef[0] + xbuff[1]*coef[1]
acc[1] = xbuff[1]*coef[0] + xbuff[2]*coef[1]We will consider for this example this mul intrinsic:
v16acc48 mul16 (v32int16 xbuff, int xstart, unsigned int xoffsets, int xoffsets_hi, int xysquare, v16int16 zbuff, int zstart, int zoffsets, int zoffsets_hi, int zstep)
To obtain the required pattern we would load lanes 0, 1, 2 and 3 in the lowest byte of the 'offsets' parameter by setting it to '0x00' and set the square parameter to '0x2110'. Additionally, the coefficient buffer needs to be accessed in the offset '0x00' for the first two lanes and have a step parameter of 1 (to place the coefficient one in the second column). Thus we would call the intrinsic in the following way:
acc = mul16 (xbuff, 0, 0x03020100, 0x47362514 , 0x2110, coef, 0, 0x00000000, 0x00000000, 1)
The call would then result in the following:
acc[0] = xbuff[0] * coef[0] + xbuff[1] * coef[1]
acc[1] = xbuff[1] * coef[0] + xbuff[2] * coef[1]
acc[2] = xbuff[2] * coef[0] + xbuff[3] * coef[1]
acc[3] = xbuff[3] * coef[0] + xbuff[4] * coef[1]
acc[4] = xbuff[4] * coef[0] + xbuff[5] * coef[1]
acc[5] = xbuff[5] * coef[0] + xbuff[6] * coef[1]
acc[6] = xbuff[6] * coef[0] + xbuff[7] * coef[1]
acc[7] = xbuff[7] * coef[0] + xbuff[8] * coef[1]
acc[8] = xbuff[8] * coef[0] + xbuff[9] * coef[1]
acc[9] = xbuff[9] * coef[0] + xbuff[12] * coef[1]
acc[10] = xbuff[10] * coef[0] + xbuff[11] * coef[1]
acc[11] = xbuff[11] * coef[0] + xbuff[16] * coef[1]
acc[12] = xbuff[12] * coef[0] + xbuff[13] * coef[1]
acc[13] = xbuff[13] * coef[0] + xbuff[20] * coef[1]
acc[14] = xbuff[14] * coef[0] + xbuff[15] * coef[1]
acc[15] = xbuff[15] * coef[0] + xbuff[24] * coef[1]If we extend the previous example with 4 tap filter, and keep the same data precision (16bit real x real FIR) we would require the following pattern:
acc[0] = xbuff[0]*coef[0] + xbuff[1]*coef[1] + xbuff[2]*coef[2] + xbuff[3]*coef[3]
acc[1] = xbuff[1]*coef[0] + xbuff[2]*coef[1] + xbuff[3]*coef[2] + xbuff[4]*coef[3]
...In order to know which multiplication we can use we need to calculate the output lanes, using the inverse formula for calculating cols.
m=1 if (data_size == 32) m*=2; if (coeff_size == 32) m*=2; if (data_complex) m*=2; if (coeff_complex) m*=2; cols = 32/(m*lanes) We already know that we want 4 columns, so, with m=1, lanes has to be 8.
We will therefore consider this mul intrinsic:
v8acc48 mul8 (v64int16 xbuff, int xstart, unsigned int xoffsets, int xstep, unsigned int xsquare, v16int16 zbuff, int zstart, unsigned int zoffsets, int zstep)
We will use the 16bx16b data selection scheme. In the next table we show the indexes of the x vector that we want. Our aim is now to find a combination of xstart, xoffset, xstep and xsquare to get this addressing.
| col | 0 | 1 | 2 | 3 | |
|---|---|---|---|---|---|
| lane | |||||
| acc[0] | x[0] | x[1] | x[2] | x[3] | |
| acc[1] | x[1] | x[2] | x[3] | x[4] | |
| acc[2] | x[2] | x[3] | x[4] | x[5] | |
| acc[3] | x[3] | x[4] | x[5] | x[6] | |
| acc[4] | x[4] | x[5] | x[6] | x[7] | |
| acc[5] | x[5] | x[6] | x[7] | x[8] | |
| acc[6] | x[6] | x[7] | x[8] | x[9] | |
| acc[7] | x[7] | x[8] | x[9] | x[10] |
We realize that we need an "x_start" of 0 because it's the only way to have a 0 at the cell of coordinates (acc_0,col_0).
If we take a closer look we see that the cell with coordinates (acc_1,col_0) requires a "1". By inspecting the 16bx16b data selection scheme we find that this is not possible because
Formula is:
if (r % 2 == 0):
offset = offs[r]*2
else:
offset = offs[r]*2 + (offs[r-1] + 1)*2
idx[r,c] = start + offset + c/2*xstep + c%2
By substituting start = 0, c = 0, r=1
idx[r,c] = offs[r]*2 + (offs[r-1] + 1)*2And we realize that since everything is multiplied by 2, we will never get a 1 in this cell.
Thankfully we can correct this by using the xsquare parameter, which permutes 4 elements at a time as explained again in 16bx16b data selection scheme, and works in blocks of 2x2 matrixes, starting at the corner (acc_0,col_0) and moving with a stride of 2 in x and y directions.
With this idea in mind we try to achieve the following pattern using xstart,xoffsets and xstep:
| col | 0 | 1 | 2 | 3 | |
|---|---|---|---|---|---|
| lane | |||||
| acc[0] | x[0] | x[1] | x[2] | x[3] | |
| acc[1] | x[2] | x[3] | x[4] | x[5] | |
| acc[2] | x[2] | x[3] | x[4] | x[5] | |
| acc[3] | x[4] | x[5] | x[6] | x[7] | |
| acc[4] | x[4] | x[5] | x[6] | x[7] | |
| acc[5] | x[6] | x[7] | x[8] | x[9] | |
| acc[6] | x[6] | x[7] | x[8] | x[9] | |
| acc[7] | x[8] | x[9] | x[10] | x[11] |
And then we apply a square of 0x2110 such that
| A | B |
| C | D |
Becomes this:
| A | B |
| B | C |
Thus achieving the following index addresssing:
| col | 0 | 1 | 2 | 3 | |
|---|---|---|---|---|---|
| lane | |||||
| acc[0] | x[0] | x[1] | x[2] | x[3] | |
| acc[1] | x[1] | x[2] | x[3] | x[4] | |
| acc[2] | x[2] | x[3] | x[4] | x[5] | |
| acc[3] | x[3] | x[4] | x[5] | x[6] | |
| acc[4] | x[4] | x[5] | x[6] | x[7] | |
| acc[5] | x[5] | x[6] | x[7] | x[8] | |
| acc[6] | x[6] | x[7] | x[8] | x[9] | |
| acc[7] | x[7] | x[8] | x[9] | x[10] |
Remember that xoffset,xstart and xstep participate only in the first permutation, hence we choose them to create the first table. The chosen ones are:
xstart = 0
xstep = 2
xoffset = 0x03020100I suggest to try substituting those parameters into the 16bx16b data selection scheme and see that you get the same result as in the example.
Z buffer follows the general scheme. What we want is the following addressing:
| col | 0 | 1 | 2 | 3 | |
|---|---|---|---|---|---|
| lane | |||||
| acc[0] | z[0] | z[1] | z[2] | z[3] | |
| acc[1] | z[0] | z[1] | z[2] | z[3] | |
| acc[2] | z[0] | z[1] | z[2] | z[3] | |
| acc[3] | z[0] | z[1] | z[2] | z[3] | |
| acc[4] | z[0] | z[1] | z[2] | z[3] | |
| acc[5] | z[0] | z[1] | z[2] | z[3] | |
| acc[6] | z[0] | z[1] | z[2] | z[3] | |
| acc[7] | z[0] | z[1] | z[2] | z[3] |
And hence we will choose
zstart = 0
zstep = 1
zoffset = 0x0acc = mul8 (xbuff, 0, 0x03020100, 0x2110, coef, 0, 0x00000000, 1)
The call would then result in the following:
acc[0] = xbuff[0] * coef[0] + xbuff[1] * coef[1] + xbuff[2] * coef[2] + xbuff[3] * coef[3]
acc[1] = xbuff[1] * coef[0] + xbuff[2] * coef[1] + xbuff[3] * coef[2] + xbuff[4] * coef[3]
acc[2] = xbuff[2] * coef[0] + xbuff[3] * coef[1] + xbuff[4] * coef[2] + xbuff[5] * coef[3]
acc[3] = xbuff[3] * coef[0] + xbuff[4] * coef[1] + xbuff[5] * coef[2] + xbuff[6] * coef[3]
acc[4] = xbuff[4] * coef[0] + xbuff[5] * coef[1] + xbuff[6] * coef[2] + xbuff[7] * coef[3]
acc[5] = xbuff[5] * coef[0] + xbuff[6] * coef[1] + xbuff[7] * coef[2] + xbuff[8] * coef[3]
acc[6] = xbuff[6] * coef[0] + xbuff[7] * coef[1] + xbuff[8] * coef[2] + xbuff[9] * coef[3]
acc[7] = xbuff[7] * coef[0] + xbuff[8] * coef[1] + xbuff[9] * coef[2] + xbuff[10] * coef[3]For symmetric FIR filter implementations that need to compute symmetric terms and a center tap in the same instruction, a special mode where the uct_col variable is used is required. The center tap terms will be selected from the pre-computed column offsets in the Y buffer using the uct_col parameter (immediate parameter). For instance, if a given intrinsic takes 4 columns of the X and Y buffers:
Besides the distinctions above, there are also a few other variations of the intrinsics which don't change their functionality but allow for more flexibility with buffer sizes, types and data selection.
There are two version of the intrinsics without pre-adding/subtraction, using two different sized vectors for the X buffer, for example for this intrinsic in small and large X buffer.
For intrinsics using input from both an X and Y buffer, there is also a second version using just an X buffer with twice the size. In this case the data selection for X and Y are done from this single buffer.
Here are a few detailed examples with increasing complexity using the intrinsics :
16 bit complex by 16 bit complex multiplication
16 bit complex by 16 bit real multiplication with pre-adding from X and Y buffers
16 bit complex by 16 bit real multiplication with partial pre-adding from Y buffer with X buffer conjugation
| acc | Running accumulation vector (4 x cint48 lanes) | Valid bits: All. |
| xbuff | Input buffer of 32 elements of type cint16 | Valid bits: All. |
| xstart | Starting position offset applied to all lanes of input from X buffer | Valid bits: 5b LSB. |
| xoffsets | 4b offset for each lane in the xbuffer. LSB apply to first lane | Valid bits: 16b LSB. |
| xstep | Step between each column for selection in the xbuffer | Valid bits: 4b LSB. |
| zbuff | Input buffer of 8 elements of type cint16 | Valid bits: All. |
| zstart | Starting position offset applied to all lanes for input from Z buffer | Valid bits: 3b LSB. |
| zoffsets | 4b offset for each lane, applied to input from Z buffer. LSB apply to first lane | Valid bits: 16b LSB. |
| zstep | Step between each column for selection in the zbuffer | Valid bits: 4b LSB. |
The input data is read from the X and Z buffers. The indices to access the X buffer are determined based on xstart, xoffsets and xstep. Assuming that IN,M denotes the buffer indices for xN,M in (Eq.1):
| l0,0 | l0,1 |
|---|---|
| (x0+xstart) mod 32 | (x0+xstart+xstep) mod 32 |
| l1,0 | l1,1 |
|---|---|
| (x1+xstart) mod 32 | (x1+xstart+xstep) mod 32 |
| l2,0 | l2,1 |
|---|---|
| (x2+xstart) mod 32 | (x2+xstart+xstep) mod 32 |
| l3,0 | l3,1 |
|---|---|
| (x3+xstart) mod 32 | (x3+xstart+xstep) mod 32 |
| buffer | . | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| xbuff (HI) | D16 | D17 | D18 | D19 | D20 | D21 | D22 | D23 | D24 | D25 | D26 | D27 | D28 | D29 | D30 | D31 |
| xbuff (LO) | D0 | D1 | D2 | D3 | D4 | D5 | D6 | D7 | D8 | D9 | D10 | D11 | D12 | D13 | D14 | D15 |
| coeffs | ||||||||
|---|---|---|---|---|---|---|---|---|
| zbuff | C0 | C1 | C2 | C3 | C4 | C5 | 0 | 0 |
| xstart | x3 | x2 | x1 | x0 | xstep | zstart | z3 | z2 | z1 | z0 | zstep |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 2 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| l0,0 | l0,1 |
|---|---|
| 0 | 1 |
| l1,0 | l1,1 |
|---|---|
| 1 | 2 |
| l2,0 | l2,1 |
|---|---|
| 2 | 3 |
| l3,0 | l3,1 |
|---|---|
| 3 | 4 |
| acc | Running accumulation vector (4 x cint48 lanes) | Valid bits: All. |
| xbuff | Input buffer of 16 elements of type cint16 | Valid bits: All. |
| xstart | Starting position offset applied to all lanes of input from X buffer | Valid bits: 4b LSB. |
| xyoffsets | 4b offset for each lane, applied to both x and y buffers. LSB apply to first lane | Valid bits: 16b LSB. |
| xystep | Step between each column for selection in the x and y buffers | Valid bits: 4b LSB. |
| ybuff | Right input buffer of 16 elements of type cint16 | Valid bits: All. |
| ystart | Starting position offset applied to all lanes for input from Y buffer | Valid bits: 4b LSB. |
| zbuff | Input buffer of 16 elements of type int16 | Valid bits: All. |
| zstart | Starting position offset applied to all lanes for input from Z buffer | Valid bits: 4b LSB. |
| zoffsets | 4b offset for each lane, applied to input from Z buffer. LSB apply to first lane | Valid bits: 16b LSB. |
| zstep | Step between each column for selection in the zbuffer | Valid bits: 4b LSB. |
| buffer | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| xbuff | D0 | D1 | D2 | D3 | D4 | D5 | D6 | D7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ybuff | D8 | D9 | D10 | D11 | D12 | D13 | D14 | D15 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| coeffs | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| zbuff | C0 | C1 | C2 | C3 | C4 | C5 | C6 | C7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| xstart | xy3 | xy2 | xy1 | xy0 | xystep | ystart | zstart | z3 | z2 | z1 | z0 | zstep |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 2 | 1 | 0 | 1 | 15 | 0 | 0 | 0 | 0 | 0 | 1 |
| acc | Running accumulation vector (4 x cint48 lanes) | Valid bits: All. |
| xbuff | Input buffer of 32 elements of type cint16 | Valid bits: All. |
| xstart | Starting position offset applied to all lanes of input from X buffer | Valid bits: 5b LSB. |
| xyoffsets | 4b offset for each lane, applied to both x and y buffers. LSB apply to first lane | Valid bits: 16b LSB. |
| xystep | Step between each column for selection in the x and y buffers | Valid bits: 4b LSB. |
| ystart | Starting position offset applied to all lanes for input from Y buffer | Valid bits: 5b LSB. |
| ctap | Selector for partial pre-substraction | Valid bits: 4b LSB. |
| zbuff | Input buffer of 16 elements of type int16 | Valid bits: All. |
| zstart | Starting position offset applied to all lanes for input from Z buffer | Valid bits: 4b LSB. |
| zoffsets | 4b offset for each lane, applied to input from Z buffer. LSB apply to first lane | Valid bits: 16b LSB. |
| zstep | Step between each column for selection in the zbuffer | Valid bits: 4b LSB. |
The contents of the input buffers will be considered as follows :xbuff (contains DXs of type cint16)
| buffer | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| xbuff (HI) | D16 | D17 | D18 | D19 | D20 | D21 | D22 | D23 | D24 | D25 | D26 | D27 | D28 | D29 | D30 | D31 |
| xbuff (LO) | D0 | D1 | D2 | D3 | D4 | D5 | D6 | D7 | D8 | D9 | D10 | D11 | D12 | D13 | D14 | D15 |
| coeffs | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| zbuff | C0 | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 | C11 | C12 | C13 | C14 | C15 |
-The pattern for the coefficients from the Z buffer is 0x3310 so that will be the zoffsets value. Similarly, it will be 0x6420 for the xyoffsets. -The first value from zbuff is C0 so zstart=0 and similarly xstart=0. -For the pre-add we start at D25 so ystart=25. -The step between columns is 2 for zbuf values and 1 for xbuf and ybuf values so zstep=2 and xystep=1. -Finally, we want to start at D15 for the final column so ctap will be set to 15.This gives this usage of the intrinsic :acc = mul4_sym_ct_cn(xbuff, 0, 0x6420, 1, 25, 15, zbuff, 0, 0x3310, 2);

