|
AI Engine API User Guide (AIE-API) 2024.1
|
|
AI Engine API User Guide (AIE-API) 2024.1
|
The AIE API encapsulates the matrix multiplication functionality in the aie::mmul class template.
This class template is parametrized with the matrix multiplication shape (MxKxN), the data types and, optionally, the requested accmululation precision. The resulting class defines a function that performs the multiplication and a data type for the result that can be converted to an accumulator/vector. The function interprets the input vectors as matrices as described by the shape parameters.
The following code snippet shows a portable sample blocked multiplication using the aie::mmul class. The matrices are assumed to be pre-tiled as defined by the mmul shape (MxK for A, KxN for B, and MxN for C).
Classes | |
| struct | aie::mmul< M_Elems, K_Elems, N_Elems, TypeA, TypeB, AccumTag > |
| Type that encapsulates a blocked matrix multiplication C = A x B. More... | |
| Arch. | 8b x 4b | 8b x 8b | 16b x 8b | 8b x 16b | 16b x 16b | 32b x 16b | 16b x 32b | 32b x 32b | bfloat16 x bfloat16 | float x float |
|---|---|---|---|---|---|---|---|---|---|---|
| AIE | 4x8x4 4x16x4a 8x8x4a 2x8x8 4x8x8a 1x16x8 2x16x8a 4x16x8a | 4x4x4 8x4x4a 4x8x4a 4x4x8a | 4x4x8a 4x4x4a 8x8x1ab | 4x4x4a 2x4x8a 4x4x8a 4x2x8a 8x8x1ab | 2x4x8a 4x4x4a 4x2x4a 2x2x4 2x4x4a 4x4x2a 2x2x8a | 4x2x2 2x4x8a 4x4x4a | 4x2x4a 2x2x2 2x4x2a 2x8x2a 4x2x2a 4x4x2a 2x4x4a 4x4x1a | 4x2x4a 2x2x2a 2x4x2ab 2x8x2ab 4x2x2a 4x4x2a 2x4x4a 4x4x1ab | ||
| AIE-ML | 4x16x8 8x16x8a 4x32x8ab | 4x8x4ab 4x16x4ab 8x8x4ab 2x8x8 4x8x8 8x8x8a 1x16x8ab 2x16x8ab 4x16x8ab | 4x4x4ab 8x4x4ab 4x8x4 4x4x8 8x4x8ab 2x8x8 | 4x4x8ab 4x4x4ab | 4x4x4 2x4x8 4x4x8ab 4x2x8 8x2x8a 8x1x8ab | 2x4x8 4x4x8ab 4x4x4 4x2x4 4x1x8ab | 2x4x8 4x4x4 | 4x2x4a 4x4x4ab 8x2x4a 4x1x8ab 8x1x8ab | 4x8x4 8x8x4a 4x16x8ab | 4x8x4 4x1x4b 4x1x8ab |
| Arch. | 16b x c16b | 16b x c32b | c16b x 16b | c16b x c16b | c16b x 32b | c16b x c32b | 32b x c16b | 32b x c32b | c32b x 16b | c32b x c16b | c32b x 32b | c32b x c32b | float x cfloat | cfloat x float | cfloat x cfloat |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AIE | 4x2x2 4x4x4a 4x4x1 | 2x4x2a 2x4x4a 2x8x2a 4x4x2a 4x4x1a | 2x2x4 2x2x8a 2x4x4a 2x4x8a 4x2x4a 4x4x2a 4x4x4a | 2x2x2 2x4x2a 2x8x2a 2x4x4a 4x2x2a 4x4x2a 4x2x4a 4x4x1a | 2x2x2 2x4x2a 2x8x2a 2x4x4a 4x2x2a 4x4x2a 4x2x4a 4x4x1a | 2x2x2a 2x4x2a 4x2x1a | 2x2x2 2x4x2a 2x8x2a 2x4x4a 4x2x2a 4x4x2a 4x2x4a 4x4x1a | 2x2x2a 2x4x2a 4x2x1a | 2x4x2a 2x8x2a 2x4x4a 4x4x2a | 2x2x2a 2x4x2a 4x4x1a | 1x2x2 2x2x2a 2x4x2a 4x4x1a | 1x2x2a 2x2x1a 2x2x1 | 2x2x2a 2x4x2a 4x2x1a | 2x2x2a 2x4x2a 4x4x1a 2x4x1ab | 2x2x2a 2x2x4a 2x4x2a 4x2x2a 4x2x1a |
| AIE-ML | 2x4x8ab 4x4x4ab | 1x4x8ab 2x4x8ab | 1x2x4ab 1x2x8ab 2x2x8ab 1x4x8ab 2x4x8ab | 1x2x8ab |
Below is an example of an optimized bfloat16 GEMM kernel in which both input matrices, A and B, are addressed in the following 4D patterns:
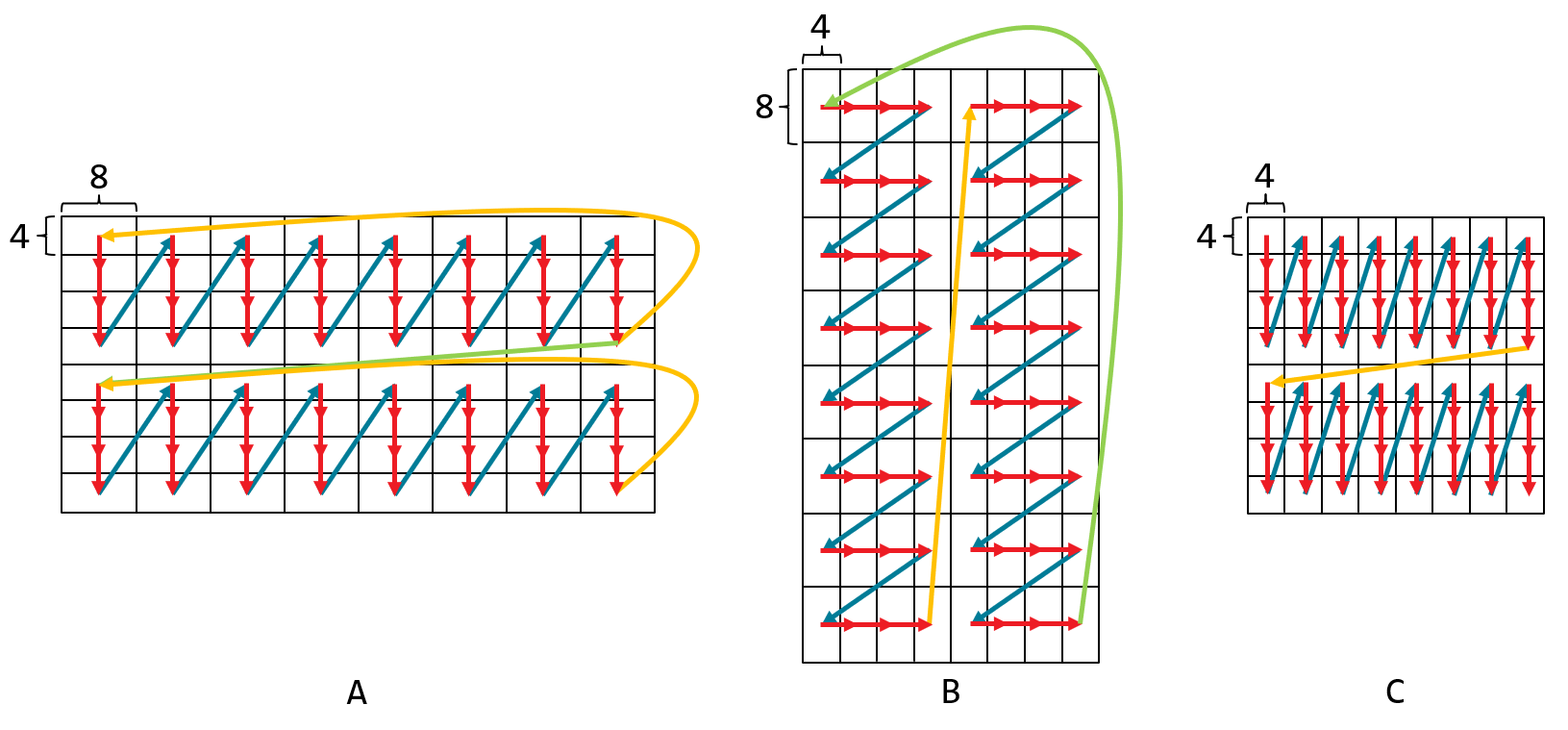
It is assumed that the data for both input matrices are pre-tiled and that the tiles are laid out in column-major order in memory.
AIE-ML introduced hardware support for sparse matrix multiplication. For an M x K x N matrix multiplication with A being M x K, B being K x N, and C being M x N, a sparse B matrix may be stored in memory using a data layout which avoids storing zero values.
| Arch. | 8b x 4b | 8b x 8b | 16b x 8b | 16b x 16b | bfloat16 x bfloat16 |
|---|---|---|---|---|---|
| AIE-ML | 4x32x8 | 4x16x8 8x16x8a 4x16x16ab | 2x16x8 4x16x8a | 2x8x8 4x8x8a 2x8x16ab | 4x16x4 4x16x8ab |
The following example shows an optimized int8 * sparse int8 GEMM:
| struct aie::mmul |
Type that encapsulates a blocked matrix multiplication C = A x B.
Objects of this type encapsulate the current result of the multiplication. The first result is computed with the mul method. New multiplications can be accumulated using the mac method.
| M_Elems | Rows in matrix A. |
| K_Elems | Columns in matrix A / Rows in matrix B. |
| N_Elems | Columns in matrix B. |
| TypeA | Type of the elements in matrix A. It must meet aie::ElemBaseType. |
| TypeB | Optional. Type of the elements in matrix B. By default is the same as TypeA. It must meet aie::ElemBaseType. |
| AccumTag | Optional. Type of the elements of the accumulator that contains the results to be written in matrix C. It must meet aie::AccumElemBaseType. If not specified, it uses the default accumulation type for multiplications of TypeA x TypeB. |
Public Types | |
| using | accum_type = typename mmul_impl::accum_type |
| using | mmul_impl = detail::mmul< M_Elems, K_Elems, N_Elems, TypeA, TypeB, detail::to_native_accum_bits_for_mul_types_tag< TypeA, TypeB, AccumTag >()> |
Public Member Functions | |
| mmul () | |
| Constructor. | |
| mmul (const accum_type &acc) | |
| Constructor. | |
| mmul (const binary_op< accum_type, bool, Operation::Zero > &op) | |
| Constructor. | |
| template<typename T > | |
| mmul (const vector< T, size_C > &v, int shift=0) | |
| Constructor. | |
| template<VectorOrOp VecA, VectorOrOp VecB> requires (VecA::size() == size_A && VecB::size() == size_B && std::is_same_v<typename VecA::value_type, TypeA> && std::is_same_v<typename VecB::value_type, TypeB>) | |
| void | mac (const VecA &a, const VecB &b) |
| Multiply the two given matrices and add it to the result. | |
| template<VectorOrOp VecA, SparseVectorOrOp VecB> requires (arch::is(arch::AIE_ML) && VecA::size() == size_A && VecB::size() == size_B && std::is_same_v<typename VecA::value_type, TypeA> && std::is_same_v<typename VecB::value_type, TypeB>) | |
| void | mac (const VecA &a, const VecB &b) |
| Multiply the two given matrices and add it to the result. | |
| template<VectorOrOp VecA, VectorOrOp VecB> requires (VecA::size() == size_A && VecB::size() == size_B && std::is_same_v<typename VecA::value_type, TypeA> && std::is_same_v<typename VecB::value_type, TypeB>) | |
| void | mul (const VecA &a, const VecB &b) |
| Initialize the result value with the multiplication of the two given matrices. | |
| template<VectorOrOp VecA, SparseVectorOrOp VecB> requires (arch::is(arch::AIE_ML) && VecA::size() == size_A && VecB::size() == size_B && std::is_same_v<typename VecA::value_type, TypeA> && std::is_same_v<typename VecB::value_type, TypeB>) | |
| void | mul (const VecA &a, const VecB &b) |
| Initialize the result value with the multiplication of the two given matrices. | |
| operator accum_type () const | |
| Conversion operator to accumulator. | |
| mmul & | operator= (const accum_type &acc) |
| Reinitialize the mmul object using the given accumulator. | |
| accum_type | to_accum () const |
| Return the result of the multiplication as an accumulator. | |
| template<typename T > | |
| vector< T, size_C > | to_vector (int shift=0) const |
| Return the result of the multiplication as a vector of the requested type. | |
Static Public Member Functions | |
| static constexpr unsigned | size () |
| Returns number of elements in matrix C. | |
Static Public Attributes | |
| static constexpr unsigned | K = K_Elems |
| Number of columns in matrix A, and number of rows in matrix B. | |
| static constexpr unsigned | M = M_Elems |
| Number of rows in matrix A. | |
| static constexpr unsigned | N = N_Elems |
| Number of columns in matrix B. | |
| static constexpr unsigned | size_A = M * K |
| Number of elements in matrix A. | |
| static constexpr unsigned | size_B = K * N |
| Number of elements in matrix B. | |
| static constexpr unsigned | size_C = M * N |
| Number of elements in matrix C. | |
| using aie::mmul< M_Elems, K_Elems, N_Elems, TypeA, TypeB, AccumTag >::accum_type = typename mmul_impl::accum_type |
| using aie::mmul< M_Elems, K_Elems, N_Elems, TypeA, TypeB, AccumTag >::mmul_impl = detail::mmul<M_Elems, K_Elems, N_Elems, TypeA, TypeB, detail::to_native_accum_bits_for_mul_types_tag<TypeA, TypeB, AccumTag>()> |
|
inline |
Constructor.
Data is undefined.
|
inline |
Constructor.
Data is initialized from the given accumulator.
Data is expected to be row-major layout.
| acc | Accumulator data is initialized from. |
|
inline |
Constructor.
Data is initialized from the given operation modifier.
| op | aie::op_zero operation. |
|
inline |
Constructor.
Data is initialized from the given vector.
Data is expected to be row-major layout.
| v | Vector data is initialized from. |
| shift | Upshift in bits to be applied to input data. This parameter is ignored for floating-point types. |
|
inline |
Multiply the two given matrices and add it to the result.
| a | Represents the A input matrix with row-major data layout. The number of elements must be mmul::size_A (M * K). It must meet aie::VectorOrOp. |
| b | Represents the B input matrix with row-major data layout. The number of elements must be mmul::size_B (K * N). It must meet aie::VectorOrOp. |
|
inline |
Multiply the two given matrices and add it to the result.
Matrix B is sparse.
| a | Vector that represents the A input matrix. |
| b | Sparse vector that represents the B input matrix. |
|
inline |
Initialize the result value with the multiplication of the two given matrices.
| a | Represents the A input matrix with row-major data layout. The number of elements must be mmul::size_A (M * K). It must meet aie::VectorOrOp. |
| b | Represents the B input matrix with row-major data layout. The number of elements must be mmul::size_B (K * N). It must meet aie::VectorOrOp. |
|
inline |
Initialize the result value with the multiplication of the two given matrices.
Matrix B is sparse.
| a | Vector that represents the A input matrix. |
| b | Sparse vector that represents the B input matrix. |
|
inline |
Conversion operator to accumulator.
|
inline |
Reinitialize the mmul object using the given accumulator.
| acc | Accumulator data is initialized from. |
|
inlinestaticconstexpr |
Returns number of elements in matrix C.
|
inline |
Return the result of the multiplication as an accumulator.
|
inline |
Return the result of the multiplication as a vector of the requested type.
| shift | Downshift in bits to be applied to output data. This parameter is ignored for floating-point types. |
|
staticconstexpr |
Number of columns in matrix A, and number of rows in matrix B.
|
staticconstexpr |
Number of rows in matrix A.
|
staticconstexpr |
Number of columns in matrix B.
|
staticconstexpr |
Number of elements in matrix A.
|
staticconstexpr |
Number of elements in matrix B.